カンムで使ってるユーザーセグメントを分ける為のクエリ(1)
実績系の集計 は前回書いたんだけど、ユーザーセグメントを分けるクエリ、ユーザーセグメントの前月比較、継続率を見る為のクエリ、というのは少し思考方法が異なるなと思ったので再度書く。
あと前回実データを作るのが本当に(本当に)大変だったので今回は可能な限りCTEのみで済ませる形でトライする。
なぜユーザーセグメントを分けるのか
一言でいうと、「より便利にサービスを使ってもらう為に何が必要かの議論の土台を作る為」だと考えている。新しい機能を検討する、新しいキャンペーンをやってみる、そういった時に「何があればより便利だと感じてもらえて使い続けてくれるようになるか」という定量的土台があるとより生産的な議論できるよね、という話だ。どのセグメントのどの数字を上げるべきなのか、その数字を上げる為に打つ施策は何か、施策後の検証はこれで良いのか、その数値を上げた先にプロダクトとしてどのような形になっていくのか、こういった事を考える際の足場となるものという位置づけ。なのでユーザーセグメントを分ける事自体にあまり意味はない。足場があっても建築しないのであれば意味がないのと同じで、建築を予定している建物に応じて作業しやすい足場を作る事が重要になる。
もちろん新機能や新キャンペーンが生まれる背景には定性調査も重要だと考えており、それは この記事に書いた んだけど、一定稼働ユーザー数があるのであれば、定量面からのアプローチも同じように重要だと認識している。
Facebookの「ユーザーが14人以上と友だちになると、継続率が途端に高くなる」、Twitterの「初日に5人以上フォローしたユーザーは継続率が高い」等は有名でその発見から目指すべき指標をマジックナンバーと呼び、その指標を高める事を目標として機能改善をしたという話はよく聞く。個人的にはマジックナンバーという単語はあまり好きではなく、どちらかというと「ユースケースの転換点」と表現した方が良いのではないかな、という気持ちがある。
なんかこの章だけで一つ記事を書けそうなので別の機会にちゃんと書く事にして、本題に進みたい。ザックリ見てみる為のクエリの話はコンテクストにあまり依存せず普遍的に役に立ちそうなので、まずはその話をしたいんですよ。
前提
まず、「ユーザーセグメント」という言葉が若干曖昧なのでこれを書き下すと「各ユーザーを特定期間の行動を含む複数の属性で各カテゴリに分類したもの。具体的にはuser idを一意なキーにした(user id, attribute a, attribute b, …., attribute z)というタプルの集合を作る事。」という意味だとする。この集合ができれば後は属性別に集計するだけなので、まずはこの集合を作る事にフォーカスすれば良い。例えば、n月の購入金額帯別 x 登録月-n月別とか、登録月の特定アクション(follow/post/rt/like)回数帯 x n+3ヶ月の特定アクション(follow/post/rt/like)回数帯別、とか。
重要なポイントとして集計直前の集合は user_id で一意になるようにするという部分。ここだけは気をつけたい。joinのキーを間違えてる、とある属性を取ってくるCTEの中でuser idが一意になってない、等発生しえるのでひとかたまりSQLを書く毎に検算するのが良い。
以下で「最初から知っておきたかったクエリのTips」「ユーザーセグメントに分ける」「ユーザーセグメント別に前月対比を見る」「ユーザーセグメント別に継続率を見る」というクエリを解説する。
最初から知っておきたかったクエリのTips
以下は自分がクエリ書く際に"役に立つ方"だと思っているTips。なお、全てPostgreSQL 12.3で実施するがBigQueryに移植するのはそこまで難しくないと思う(MySQLはわからない)。
CTE+cross joinを使った変数定義
n月起点のデータを集計したんだけどn+1月にずらしたいなとなった時にクエリの条件を全部書き直してませんか?そして結果出た後に数値がおかしいなと思い再度クエリを見直したら一箇所修正できていなかった、そんなケースありませんか?以下のようにCTEとcross joinを使うとクエリの先頭で定義した時間だけ意識すれば良くなるのでミスも減るしクエリの時期をズラした展開がしやすいです。
with
args(from_dt, to_dt) as (
select '2020-01-01 00:00:00' at time zone 'jst', '2020-02-01 00:00:00' at time zone 'jst'
)
select
p.user_id
, count(*) as cnt
from purchase p
cross join args a
where p.purchased_at >= a.from_dt
and p.purchased_at < a.to_dt
group by
p.user_id
上の例では一箇所しか from_dt と to_dt を利用していないのでメリットをそこまで感じないかもしれないんだけど、例えば当月と前月のデータを取得して比較する際に当月のCTEと前月のCTEを作る際に以下のように書ける。
with
args(from_dt, to_dt) as (
select '2020-01-01 00:00:00' at time zone 'jst', '2020-02-01 00:00:00' at time zone 'jst'
)
, target_mt_purchase as (
select
p.user_id
, count(*) as cnt
from purchase p
cross join args a
where p.purchased_at >= a.from_dt
and p.purchased_at < a.to_dt
group by
p.user_id
)
, last_mt_purchase as (
select
p.user_id
, count(*) as cnt
from purchase p
cross join args a
where p.purchased_at >= a.from_dt + '-1month'
and p.purchased_at < a.to_dt + '-1month'
group by
p.user_id
)
....
変数的な扱いにしておく事で変数名に意味を込めれるし、クエリを修正したい場合変更箇所を局所化できるので便利。また、以下のように書くとダッシュボードに配置しておく月次の実績確認用クエリを毎月月初に修正する必要がなくなるので便利。
with
args(from_dt, to_dt) as (
select date_trunc('month', current_timestamp at time zone 'jst'), current_timestamp at time zone 'jst'
)
...
CTEを使った関数やクエリの実験
「あれ、この関数ってどういう挙動だっけな」となった事ないですか?「相関サブクエリどうやって書けば良いんだっけな」とか「このクエリ、意図した通りに動作するか?」となったことは?そんなとき実データで検証するよりも自分で軽くデータ作って検証できると嬉しい。ここでもCTEで適当なデータを作るのは活躍する。
以下はBigQueryまだ慣れてない時に日付操作の素振りをしたクエリ。いきなり大きなクエリを書くのではなく、こういう風に細かく実験できるような型を持っておくと便利。
with
dtm as (
select timestamp('2020-07-01 00:00:00') as start
)
select
start
, datetime(start) as datetime_start
, date(start) as date_start
, datetime_add(datetime(start), interval 1 month) as datetime_add_1m
, timestamp(datetime_add(datetime(start), interval 1 month)) as timestamp_datetime_add_1m
from dtm
例えば not exists を使って最小値が含まれるレコードってどうやってとってくるっけな…となった場合以下のように実験に必要な最小限のレコードをCTEで定義して軽く実行してみるとより理解が進む。
with
employee(id, name) as (
values
(1, '8maki')
, (2, 'ide')
, (3, 'js')
, (4, 'achiku')
, (5, 'moqada')
)
select
t.id
, t.name
from employee t
where not exists (
select 1
from tbl t2
where t.id > t2.id
)
distinctを使わない一意なキーに対する最大値/最小値と"同一レコード内にある別属性"
「maxで取りたいのはその数値自体じゃなくて、maxな数値を持った同一レコード内の別の属性なんだよ!」ってなったことないだろうか?「maxで集約してidを取ったあとそれを条件にして再度テーブルに対してクエリするのダルいな…」って思ったことは?「first_value() over () も良いんだけどキーで集約されないから最後 distinct するのなんか嫌だなぁ…」はどうだろう?これに関しては結果の一意性の観点から賛否ありそうなんだけど、以下のように row_number() over (partition by .. order by ... desc/asc) を使うとdistinctやmaxを使わずにサクッと取れて便利。
with
employee(id, name) as (
values
(1, '8maki')
, (2, 'ide')
, (3, 'js')
, (4, 'achiku')
, (5, 'moqada')
)
select
a.id
, a.name
, a.rn
from (
select
t.id
, t.name
, row_number() over (order by t.id desc) as rn
from employee t
) a
where a.rn = 1
ただし、以下のような状態のレコードだと、関数の仕様として moqada-v1 / moqada-v2 どちらが選択されるかは任意になってしまうので注意が必要。データの制約によっては結果が変化しうるので、ザックリ出すだけならば良いが、精緻な数字が必要な場合はデータの制約を確認しながら用法用量を守って使いましょう。
with
employee(id, name) as (
values
(1, '8maki')
, (2, 'ide')
, (3, 'js')
, (4, 'achiku')
, (5, 'moqada-v1')
, (5, 'moqada-v2')
)
select
a.id
, a.name
, a.rn
from (
select
t.id
, t.name
, row_number() over (order by t.id desc) as rn
from employee t
) a
where a.rn = 1
特定行動の回数に関わらず、とにかく0と1に分けたい
「回数とか合計じゃなくて発生したかしなかったかの0 or 1のフラグが付けれれば良いんですけど」となったことありませんか?case when ... then 1 else 0 end でも良いのですが sign 関数を利用すると便利です。
ビッグデータ分析・活用のためのSQLレシピ に載ってて、自分も読んだ時最初驚いたんだけど、「期間tとユーザーIDをキーにして特定行動の有無を0と1に分けておくことで、その0と1を平均すると期間t毎の継続率が出る」という使い方ができるのも面白いポイントだと思う。
ユーザーセグメントに分ける
Tipsが長くなってしまった。ここからが本題。以下のような観点でまず要件を自然言語でまとめる事をお勧めする。いきなりクエリを書き始めても良いし、やれるならやれば良いんだけど、本当にこれで意味ある数字になるのか?欲しいデータなのか?というのを自分で考える切っ掛けになるし、何より誰かにレビュー/検算してもらう際に便利。
(1) セグメントに分ける対象を定義
まずはセグメントに分ける対象ユーザーの範囲を決める。「n月に登録したユーザー」なのか「n月に行動aを1回でもしたユーザー」なのか「n-1月に行動aをx回以上したユーザー」なのか、ここを最初に明確にすることでその先の属性、特にユーザーの行動ベースに属性を集計する際にどの範囲を指定するべきかが明確になる。例えば、「n月に登録したユーザー」を行動aでセグメント分けたいとなれば、行動aはn月からn+3月までのものとする、というように、対象ユーザーによってその後の行動ベースの属性の定義を考えやすくできる。
(2) 行動ベースの属性定義
これは上でも少し書いたけど「n+1月からn+3月の間に行動aを何回したか」のような定義のこと。左記程度なら簡単なんだけど「n+1月からn+3月の間に購入金額、購入回数をベースに定義したランクがどの程度変動したか」とかになるとやっぱり自然言語で書いてあった方が分かりやすい。デモグラフィックな属性(e.g. 年齢等)に関しては自明な事が多いのであまり気にする必要はないんだけど、行動ベースの属性は定義や解釈次第で一意に定まらないので自然言語で書き下しておくとその後意図通りのクエリが書けているかのチェックにも使えて便利。
(3) 1属性1CTEでキーはユニークにする
デモグラフィックな属性も行動ベースの属性も、(1)で決めたユーザーIDで一意になっている対象者の集合を駆動表にしてそこに各CTEで定義した属性を left join していくイメージ(inner joinするとその属性を持ってない人(行動ベース属性の場合何もしていない人)が欠落するので注意)。ポイントは、1属性1CTEにするという部分。なぜ1属性1CTEにするかというと、属性を入れ替えやすいし、構造が「対象の集合、属性1の集合、属性2の集合、…、属性zの集合、最後の集計」という形で単純になるから。自分は元々ソフトウェアエンジニアとしてOLAPなSQLを書く事が多く、「1テーブルを1つのクエリで何回もSeqScan(or Table Access Full)するなんて贅沢だ!!」と思っていたくちなんだけど、分析系のクエリをPostgreSQLのread replicaに対して実行してたり、BigQueryに移行したりする中で「パフォーマンスにそこまで拘らなくてもクエリの構造自体がシンプルになってて欲しい…余計なメンタルコスト支払いたくない…」という風に思考が遷移していったのを感じる。
例
ごちゃごちゃ説明したけど見てみるのが早いと思うのでサンプルデータを元にクエリを書いて説明する。利用しているデータはこちら。
まずは対象ユーザーを定義する。ここでは2020/01に登録したユーザーを対象にする。
with
args(from_dt, to_dt) as (
select '2020-01-01 00:00:00' at time zone 'jst', '2020-02-01 00:00:00' at time zone 'jst'
)
, target_user as (
select
u.id
, u.name
, u.registered_at
from shop_user u
cross join args a
where u.registered_at >= a.from_dt
and u.registered_at < a.to_dt
)
これもコツの一つなんだけどCTEを一つ書いたらそれだけ実行する簡易なSQLで結果を確認するのが良い。この場合、本当に登録日は2020/01のみになっているのかという部分。
次に行動ベースの属性を定義する。2020/01登録ユーザーが2020/02に商品を購入した金額の合計(キャンセル等は考慮しない)をユーザーID毎に集計する。
, mt_purchase_amt as (
select
tu.id
, tu.name
, sum(t.amount) amt
from target_user tu
left join (
select
p.user_id
, p.amount
, p.item_id
from purchase p
cross join args a
where p.purchased_at >= a.from_dt + '1month'
and p.purchased_at < a.to_dt + '1month'
) t
on t.user_id = tu.id
group by
tu.id
, tu.name
)
ここのポイントは target_user で取得してきたユーザーIDを駆動表にして、2020/02の purchase を left join している部分。こうすることで「購入していない」という情報を維持したままデータを取得している。よくやってしまいがちなミスとしては purchase をサブクエリにせずに left join してから条件を絞ってしまい、「購入していない」という情報が欠落すること。これはjoinの条件にandを使うのもありなんだけど、パフォーマンスをある程度無視するなら好みの問題かなぁと思う。CRM系のデータは全て「対象は時点tにおいてxしていない」という情報も取得しないといけないので実績集計系よりも考慮点が多くてダルい。
もう一つ行動ベースの属性を定義する。2020/01登録ユーザーが2020/02に商品を区遠敷した回数の合計(キャンセル等は考慮しない)をユーザーID毎に集計する。
, mt_purchase_cnt as (
select
tu.id
, tu.name
, count(t.purchase_id) cnt
from target_user tu
left join (
select
p.user_id
, p.id as purchase_id
, p.amount
, p.item_id
from purchase p
cross join args a
where p.purchased_at >= a.from_dt + '1month'
and p.purchased_at < a.to_dt + '1month'
) t
on t.user_id = tu.id
group by
tu.id
, tu.name
)
「これ、上の金額合計と同じ軸で集計してるし上のクエリに混ぜれば良いのでは?同じクエリ内で2回も同じテーブルを読み込むのは非効率では?」という指摘は有効だと思う。正直この程度の複雑さならどちらでも良いといえば良いんだけど、そこまで大きなテーブルに対するクエリでなければ、もしくはBigQueryに入れてるのであれば、テーブルの件数と相談しながらではあるけど、構造の一貫性を重視して良いかなと考えている。
最後に mt_purchase_cnt と mt_purchase_amt を user_id でjoinして結果を集計する。この際に数値系のデータに関しては、CASE式を利用してある程度のカテゴリに分けると良いと思う。ここのカットポイントどうするのかというのは実際に数値見ながら、用途を考えながら決める。
, mt_user_segment as (
select
a.id
, case
when a.amt is null then '01_0k'
when a.amt > 0 and a.amt <= 2000 then '02_1k-2k'
when a.amt > 2000 and a.amt <= 3000 then '03_2k-3k'
when a.amt >= 3000 then '04_3k-'
end amt_type
, case
when c.cnt = 0 then '01_0'
when c.cnt = 1 then '02_1'
when c.cnt = 2 then '03_2'
when c.cnt >= 3 then '04_3-'
end cnt_type
from mt_purchase_amt a
inner join mt_purchase_cnt c
on a.id = c.id
)
select
s.amt_type
, s.cnt_type
, count(*) uu
from mt_user_segment s
group by
s.amt_type
, s.cnt_type
redashのpivotテーブルを作って簡易的なクロス集計をして感触を掴む。サンプルデータなので少なくてheat mapをする程でもなくて寂しいがuuはこれで確認できる。
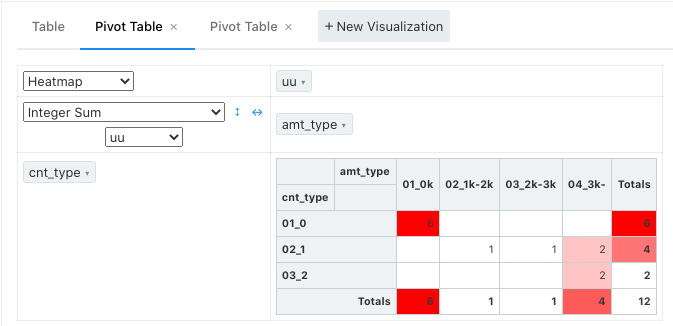
uuの全体に対する割合は Sum as Fraction of Total を選択すると綺麗に表示可能。redashのpivot内では小数点どこまで表示するかはイジれないので必要に応じてクエリ内で出力する。
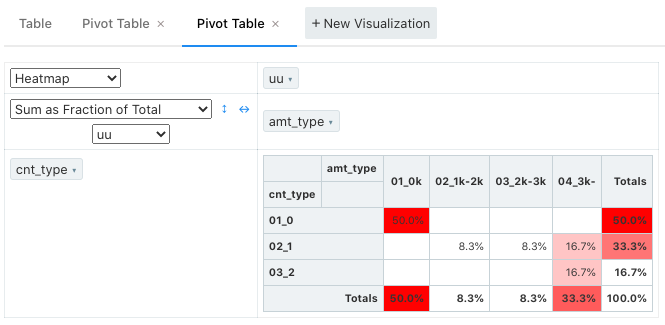
この他にも Sum as Fraction of Rows / Sum as Fraction of Columns があり、行集計の割合、列集計の割合がサクッと出せるのは良い。自分はDashboardで荒くでも良いから常時見ておきたい場合はredashのpivotで十分だと思うが、より細かく見た目を整えたりしたい場合はGoogle Spreadsheet等に貼り付けてpivotするのが良いと思う。
金額と回数のセグメントはまぁ分かった。これを購入回数とそのユーザーが最も多い回数買っている商品カテゴリにするとどうなるのか見たい。以下のCTEで1ユーザーが2020/02において最も多くの回数を買っている商品のカテゴリを出す。
, mt_purchase_item_category as (
select
b.id
, b.category
from (
select
a.id
, a.item_id
, a.category
, row_number() over (partition by a.id order by a.cnt desc) rn
from (
select
tu.id
, t.item_id
, i.category
, count(t.purchase_id) cnt
from target_user tu
left join (
select
p.user_id
, p.id as purchase_id
, p.amount
, p.item_id
from purchase p
cross join args a
where p.purchased_at >= a.from_dt + '1month'
and p.purchased_at < a.to_dt + '1month'
) t
on t.user_id = tu.id
left join item i
on i.id = t.item_id
group by
tu.id
, t.item_id
, i.category
) a
) b
where b.rn = 1
)
この形ができたら後は集計のクエリを少し修正すれば同一対象ユーザーを別のセグメントで区切ることができる。1CTE1属性だと集計のクエリの変更点が明らかなのでミスが減るのではないかと思っている。
, mt_user_segment as (
select
c.id
, case
when i.category is null then 'N/A'
else i.category
end item_type
, case
when c.cnt = 0 then '01_0'
when c.cnt = 1 then '02_1'
when c.cnt = 2 then '03_2'
when c.cnt >= 3 then '04_3-'
end cnt_type
from mt_purchase_cnt c
inner join mt_purchase_item_category i
on c.id = i.id
)
select
s.item_type
, s.cnt_type
, count(*) uu
from mt_user_segment s
group by
s.item_type
, s.cnt_type
まとめ
また長くなりすぎた。。。「ユーザーセグメント別に前月対比を見る」「ユーザーセグメント別に継続率を見る」も基本今回の応用なので次回書く。
採用している
こんなことを議論しながらユーザーの側にしかない迫真の具体性を追い求めていく職、マーケターというポジションを募集している。定量/定性両面から、ユーザーの持っている具体性に迫っていくというのはとてもおもしろいと思うので是非気になる人は応募をどうぞ!もう少し気軽に話を聞いてみたいという方は achiku までDMください!